
A friend of mine has been asking me a few questions about encoding for a paper he is working on. While I don’t understand what his research is on, all I can understand from his research is that he is working on analyzing Japanese texts and it involves understanding character encodings. Character encoding is not a topic that most native-English programmers are familiar with. The most that the average programmer will know is the existence of ASCII and UTF-8 encoding. If we are using anything beyond the English alphabets and arabic numerals (i.e. 1, 2, 3, 4, 5, 6, …) then we can utilize UTF-8, else use ASCII.
I am sure most of us has encountered the random garabage characters such as � or the □ (U+25A1) when trying to read documents that have a mix of English and some foreign language or see random garbage displayed in our media displays like the Infotainment displays when we try to listen to music from Asia.
Chinese characters not displaying correctly. Extracted from Developing Linguistic Corpora: a Guide to Good Practice
I was not aware of the existence of full-width and half-width characters till the friend asked me to briefly give an explaination on the differences between the two from a technical aspect. For those like me who weren’t aware that the Japanese mix between zenkaku (full-width) and hankaku (half-width) characters, look at the image below or visit the following webpage for more explanation: https://mailmate.jp/blog/half-width-full-width-hankaku-zenkaku-explained

As you can see, half-width characters unsurprisingly takes up less space visually than the full-width characters.
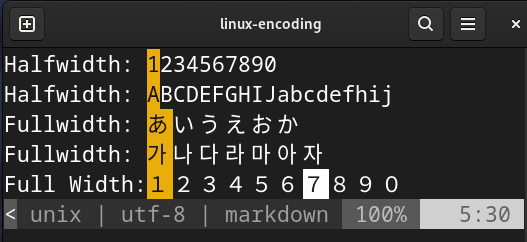
Full and Half Width encoded on UTF-8 as seen through Vim
While I have read and typed Korean during my younger years when I was forced to learn Korean, it never clicked to me how much space Korean takes up graphically. It is obvious in hindsight but it was nonetheless interesting.
There is also an implication
on the amount of data half-width and full-width characters consume (though this does depend on the encoding). For Western
audience, we know that ASCII takes up 1 byte and can be represented as a char in C.
Extending ASCII
One interesting fact about ASCII is that ASCII only maps to 128 characters (though only 95 is printable). Recall that ASCII can be represented by 1 byte which makes up of 8 bits. Doing the Math, 8 bits can represent 2^8 = 256 values. This leaves us with the remaining 128 values unmapped to anything.

ASCII Table. Extracted from Wikipedia
This allows other languages and programmers to take advantage in extending ASCII to display extra characters such as accents from European
languages such as é, è, ç, à in Latin 8 and ISO 8859 or Katakana characters in
JIS C 6220 (JIS X 0201) in 1969.
Though JIS C 6220 does change a few characters so it is not exactly an extension of ASCII. Though ignoring the few differences, we can
see that the Katakana characters are mapped in the remaining half starting from 0xA1 to 0xDF.

JIS C 6220 which is also known as JIS X 0201. Extracted from Wikipedia
ISO 8859 on the other hand such as Latin-8 seems to be a direct extension of ASCII where 0xA1 - 0xFF contains characters from several European languages such as French, Finnish and Celtic.

ISO 8859-14 (Latin-8) Encoding. Extracted from Wikipedia
Aside: UTF-8 v.s UTF-16
Based on the article I shared, half-width characters takes up 1 byte while full-width characters takes up 2 bytes (also can be called double byte character).
I do believe this depends on the encoding used. Taking a look at the size and bytes encoding, we can see that number 1 in UTF-8 encoding takes 1 and 3 bytes for half-width and full-width character repsectively
$ stat -c "%n,%s" -- halfwidth-utf8.txt fullwidth-utf8.txt
halfwidth-utf8.txt,1
fullwidth-utf8.txt,3
One confusion I had was understanding what the difference between UTF-8 and UTF-16 and the following excercise helped me understand this:
- UTF-8 encodes each character between 1-4 bytes
- UTF-16 encodes each characters between 2-4 bytes
UTF-8 and UTF-16 as you can tell are variable length meaning they take up more or less bytes depending on the character being encoded. We can
see this by comparing the number 1 arabic numeral v.s. the Chinese character for the number 1 一:
$ stat -c "%n,%s" -- halfwidth-1.txt chinese-1.md
halfwidth-1.txt,1
chinese-1.md,3
In UTF-8, 1 takes up 1 byte which is unsurprising as ASCII has great advantage in UTF-8 compared to other Asian languages such as Chinese where the character for 1 一 consumed 3 bytes.
Note: Do not attempt to display UTF-16 encoded files on the terminal without changing your locale (or whatever it is called). It will not display nicely. Vim on my machine will automatically open the file as UTF-16LE.
Let’s inspect the contents of the files between Half character 1 and Full Byte Character 1 in HEX:
$ cat halfwidth-1.txt; echo ""; xxd halfwidth-1.txt; cat fullwidth-1.txt ; echo ""; xxd fullwidth-1.txt 1 00000000: 31 1 1 00000000: efbc 91 ...
As we can see, the half-width character 1 in UTF-8 is represented as 0x31 meaning only one byte would be required. However, a full-width
digit 1 is represented as 0xEFBC91. Now let’s compared this with UTF-16:
$ cat halfwidth-utf16.txt; echo ; xxd halfwidth-utf16.txt; cat fullwidth-utf16.txt; echo; xxd fullwidth-utf16.txt
1
00000000: 0031 .1
�
00000000: ff11 ..
Note: To view UTF-16 on VIM run on command mode (i.e. press esc to exit current mode and press : to enter command mode): e ++enc=utf-16be fullwidth-utf16.txt
As expected, UTF-16 represents code points in the upper range very well where we now see 1 (full-width 1) being represented with only 2 bytes unlike the 3 that was required in UTF-8.
Though the same cannot be said for code points in the lower range such as our half-width digit 1 which now takes 2 bytes by appending 0x00 to its hex representation.
Half-Width and Full-Width in Japanese Specific Encodings
I had earlier mentioned about JIS C 6220 (JIS X 0201) which utilized the fact that the last 128 bytes of ASCII isn’t utilized which allowed
the Japanese to add Katakana support. Although it’s not a direct extension as the Japanese did changed the lower 128 characters slightly to be localized to the Japanese such as replacing
the \ with the Japanese Yen ¥. Full-Width Japanese characters apparently started to appear in 1978 starting with JIS C 6226.2) where Kanji can be displayed.
A more recent standard is the Shift-JIS in 1997 and is apparently the current second mostly used encoding among .jp (Japananese) websites.
Based on a survey on October 7 2024, Shift JIS is still used by 4.8% of .jp websites, 2.3 for
EUC-JP and the remaining going to UTF-8. As mentioned previously, it would seem to be the case for Japanese encoding such as Shift JIS, half-width characters not only have a smaller
width but also requires half the number of bytes to be represented. Half-Width characters do not imply less bytes to represent in general but for Shift-JIS, that would seem to
be the case:

Hex Representation of ア and ア. Credits to charset.7jp.net
As you may notice, I am using the same example from the article but I opted to generate my own
image. The blog for some reason decided to add 0x0D0A which corresponds to CRLF i.e. \r\n making it less obvious to readers that the full-width character takes 2 Bytes
and the half-width chaacter only takes 1 byte. As I don’t know Japanese, but according to the article both characters have the same phonetic sound. Though I am pretty sure the
two are the same in written (i.e. handwriting) language. The likely reason for this behavior is that fact that it is an extension of JIS X 0201:1997, they very same encoding
that first introduced Katakana (though the edition differs) and encodes the double-byte characters from JIS X 0208:1997 according to wikipedia.
Note: 1 byte character can also be referred as single-byte character while 2 bytes characters can be referred as double-byte characters
Based on the above image, we can make the following observations:
- Full-Width characters take 2 bytes in Shift-JIS
- Half-Width characters take 1 byte in Shift-JIS
- UTF-8 and UTF-16 do not seem very optimized to take Japanese characters taking 3 bytes and 4 bytes respectively
Unsurprisingly, Shift-JIS was designed for the Japanese and therefore are more space efficient than the more international/universal versions like UTF-8. According to my friend and the article, Japan still requires users to switch between full-width and half-width characters. I have no clue as to why but I have heard that Asian countries such as Japan and Korea can be slow to modernize their digital infrastructures despite being technology leaders and innovators. The article suggests it is due to the bureaucracy and work culture not fostering a culture to take some risks and not seeing the need to fix what isn’t broken.
The remaining content is not relevant to the title but is a refresher of Hex
Review of HEX
Computers work in binary which consists of only 0 or 1 (i.e. base 2). The decimal system we all use is base 10. Hexadecimal are base 16 and tend to be the favorite way to represent
a series of bytes due to its more compact form (or at least that’s what it seems like to me). Hexadecimal numbers have 16 values: 0-9 and A-F. In binary, a single bit can represent
2 values which can be expressed as 2^0. This means that 4 bits can represent 2^4 = 16 bits. This means a single hexidecimal digit can be represented using only 4 bits. Two
hexadecimal digit will therefore take 8 bits = 1 byte. That is why the half-character ア takes up one byte as it is 0xB1 in Shift-JIS. B1 consists of two hexadecimal digits
and hence only 8 bits and therefore 1 byte. The full-width character ア is 0x8341 which consists of 4 hexadecimal digits and therefore 4 * 4 bits = 16 bits or 2 bytes.