
In my undergraduate in Computer Science, I got the opportunity to work at IBM as a member of the Build Infrastructure Team. I had absolutely no clue what the Build Infrastructure Team is or does. Though I am no expert and I still have a difficult time explaining what I do to friends and family, I’ll try to tackle the subject to the best of my ability. This post is a precursor to an education session titled An Overview of DevOps and Builds I plan to give to new interns of the Build Infrastructure Team at IBM this May. I am hoping my actions of writing a blog will prepare me for my presentation. (On a side note, this is a good sequel to my previous blog about Software Ports)
On my first week of joining the Build Infrastructure team, I tried to search up what a Build Team does because it was not clear to me what I will be doing. I came across a paper titled Understanding and Improving Software Build Teams which examines the various Build Teams at Microsoft. It’s one of the only comprehensive pieces of information I could find about Build Infrastructure teams at the time. Little did I know that there are tons of information about Build Teams but I did not google Build Engineer.

Disclaimer:
The information presented is from publically available sources or is not a secret to the public. Any views presented are personal and do not reflect any single company or group.
Timeline
-
Overview of DevOps and Builds - From a Semi Outside Perspective
-
A Dive to the Build Process: What Goes On When You Press the Play Button
-
[Internal] Version Control and Software Tracking: Git, Github, Clearcase, ClearQuest
-
Build Automation Tool: Jenkins, Buildforge, and Github Actions
- Buildforge will be presented internally and will not be shared to the general public
What is a Build
Before we talk about what a Build team is, we first need to go to the basic question, what is a build?
You may recall when working on Java, C, or C++ you ran a Build by pressing Build, Run, or Play button

or you would “compile” your code on the terminal

But what does this actually do? As you may know, a build is just simply the process of converting your source code (i.e. .c or .java) to a binary/executable (i.e. .exe or .o). More formally (if you accept Wikipedia as credible):
In software development, a build is the process of converting source code files into standalone software artifact(s) that can be run on a computer, or the result of doing so. - Wikipedia

An executable to put it briefly is the ready to run form of a program (hence why we call it an executable). An executable consists of instructions (i.e. machine code) that consists of zeros and ones assembled in a way the CPU understands. Some common locations where executables can often be found on Unix-like Operating System (OS) under /bin, /sbin, /usr/bin, or usr/local/bin. As this is more of a brief overview about builds, I won’t delve into the structure of an executable (i.e. ELF Format. Though not like I have a good understanding of the topic either).
Note: If you want to have a more in-depth overview of how a build works, see my next post coming in the next few days.
Build Tools
Build tools are simply just tools that automate the build process but can do more than simply building a program. Some common examples of Build tools are Make, CMake, Ant, Maven, and Gradle.
Build automation is the process of automating the creation of a software build and the associated processes including: compiling computer source code into binary code, packagine binary code, and running automated tests -Wikipedia

An example of a makefile from Diablo
When working on a project, it quickly gets tedious to type the entire command to compile all your files, especially when there are a lot of files. I personally would rather just press the play button or write a shell script to compile a few files like the following:
gcc parser.c symbol_table.c assembler.c -o assembler
However, when programs get sufficiently complex and large (i.e. a couple of files with many dependencies), a build system is needed. A build system simplifies the process of building your code from compiling to running all your tests and perhaps generate documentation for it as well using tools such as JavaDocs or Doxygen.
For more in-depth look at Build Tools, I would suggest looking at a blog post titled What’s in a Build Tool by Haoyi Li. For more in-depth look at Build Systems, I suggest taking a look at a lecture from University of Victoria or from the textbook the lecture is based on titled Software Build Systems: Principles and Experience

Why Do Build Team Exists?
Build systems can get quickly complex and large such that it becomes unmanageable. Coupled with the fact that builds can take hours to build, especially with larger projects. For instance, at Microsoft, some projects can take 6 hours to build. From my experience, I’ve seen builds from 30mins to an entire day to build. This causes a lot of idling time for developers (you would be wrong to assume developers will be able to multi-task effectively plus the overhead of context switching was found to impact productivity and developers can forget on tasks they were working on).

Bugs are very common to create so a single build failure creates more delays not only in development but also increases uncertainty whether or not the new code changes will compile fine and pass all the tests. The health of your program becomes more murky and unhealthy. Clean and consistent builds are considered to be the healthy “heart” of software development. A good practice of software development is to catch errors as early as possible when they are still small and manageable.
Build teams were formed out of both necessity and frustration in the growing complexity of build systems. Though since Build teams were formed out of a reactionary response to the growing issue, roles are often ambiguous, especially in the early formations (i.e. Microsoft). Though I could not find much information about Build teams online, they are not uncommon in large organizations. They can be found in many companies such as Microsoft, Google, IBM, Facebook, Netflix, Mozilla, LinkedIn, Gnome, Eclipse, Qualcomm, VMWare
If a build team or a Build & Release team does not exist, it’ll exist within some devOps team. The main tasks of the Build team from my experience and what I read is to abstract the build complexity and to be responsible for building the entire project for all supported hardware and platforms. More on this later.
What Does the Build Team Do?
The exact role of the build teams are often found to be ambiguous and differ from each member within the team. Here are the main generalized tasks I can think of:
- monitors ci and nightly
- runs some tests and tracks down errors
- i.e. Build Verification Test (BVT)/Smoke Tests: a subset of tests that verify main/critical functionalities to ensure the build is not corrupted or bad
- maintains build and infrastructure tools and environments
What is a Nightly Build and CI Build
A nightly build (also called daily build) is a build that is performed at the end of the day in a neutral environment (an environment not used for development). The idea of building your program on a neutral environment is critical. I had experience with group members including myself where the code would not run on anyone’s computer but you swear that the code compiles and runs fine on your machine.
One key goal of a build system is that it must be repeatable. The project is built exactly the same way regardless of who and where it was built. The build must be reproducible such that I can move or copy the build system to a different server and can perform a build. Think of it as being able to clone a project from Github and being able to compile the program.

Anyhow, back to the topic of nightly builds. Nightly builds can contain more extensive testing (regression, QA, and integration) and build coverage and can produce an image/installer/executable which can be used for deployment or further testing. When performing these builds, it may be a good idea to perform a clean build since some files may not be recompiled (for some unexplainable reason) or the generated files may be “corrupted”.

An example of nightly builds that gets released to the public every single day
CI (Continuous Integrated) Builds are builds that merge all work done by developers several times a day. The idea of CI builds is to build frequently. Although the frequency varies depending on company and project, CI builds can vary from a few times a day to every single code change that gets committed or merged.
Example: Open Source Project Docker Compose: Overview of Docker Compose



The Docker team runs the CI pipeline before each PR gets merged. Though I could be wrong, you can take a look at their Jenkins server which is publically accessible:Docker Compose Jenkins Link and see for yourself (I didn’t bother to take a close look).
Findings From Microsoft About Build Teams

From the paper I linked at the start of the blog, I will like to present some findings the researchers found along with some minor commentary (I don’t wish to disclose too many details from my experience as I am still employed and wouldn’t want to risk being in odd terms):
Role Ambiguity
Since Build members’ roles are emerged and molded to fit the changing needs of their organization, the roles of the builders are hard to define. Each member’s role can also differ from the other within the same team. The role of a builder can also differ from organizations and departments. One of the ambiguities stems from their tasks that overlap with other teams. An example the paper gives is the following:
For example, coordinating code flow (i.e., source code integrations) between teams is a project management task; maintaining a build system a development task; and testing falls in the domain of quality assurance.
-Understanding and Improving Software Build Teams
Another thing that was noted in the paper was that builders were described as “generalist” or a jack of all trades. Therefore builders perform many different types of tasks but are likely not to perform as well as others who specialize in these tasks. [input personal experience when permitted].
Another finding from the paper notes that
can be abused, especially on smaller teams” (P2), where builders will likely to do a variety of tasks outside of the build-space -Understanding and Improving Software Build Teams
This finding is interesting and I can see this being applicable in some forms to my workplace. Due to the ambiguity of the tasks between various teams and the fact that other teams may not want to deal with legacy stuff, they may be dumping tasks that could be shared or simply do not make much sense to dump the work to us. Though other teams also work on tasks that encroach our domain as well so it can be quite confusing.

Job Satisfication
Due to the job ambiguity and other factors which I’ll get to, it is found that job satisfaction in the Build team was found to be low at Microsoft. I am not too surprised by this finding. When things are ambiguous and never confident in your tasks, it could take a toll on your self-confidence and satisfaction. I definitely do not see myself working in the build team forever and will probably leave or transfer to do something new one day. This can be a particular problem where experienced builders leave which goes to the next point, the knowledge sharing within the Build Team.
Intragroup Knowledge
Based on the findings, Microsoft faces similar issues found at the company I work at. There are great concerns about the speed at which knowledge is transferred. I’ve been worried about this particular problem for a while after working with a few new hires and interns who lost the benefit of in-person learning due to both the pandemic and the loss of a member. I notice there is a big knowledge gap between those who were previously interns at the team versus those who are new to the team even after they settled in the team for over a year. I think due to the nature and the breadth of tasks the job entails, it is extremely difficult to teach new hires the job in a short amount of time. Build systems can get very complex quickly and there is a lot of different tasks and solutions. Going through every single task will not be helpful to the team without first getting some experience with the build system and familiarize themselves with the ecosystem. However, the process of getting familiar with the ecosystem is a big task in itself. The reason why there is a big knowledge gap between former interns and new hires is the exposure and the differences in expectations and roles.
One thing I found particularly funny from the paper is the idea of tribal knowledge. The paper refers to tribal knowledge as the undocumented build experiences and is one of the most useful and frequently accessed sources of information. However, this causes issues because it means there will be an inherited knowledge gap between those who are experienced and those who are new to the team. Coupled with the usage of automation tools can cause the builder to be completely lost when senior builders are busy or leave the company.
“As awesome as automation is, it isolates the builder from the easy tasks that help them understand the build process…when the senior builder moves on and the difficult tasks break, the rookie is at a huge disadvantage while they try to gain tribal knowledge.”
-Understanding and Improving Build Teams
Knowledge sharing and the type of work the job entails makes it hard for new builders to start working within their first month or two. I’ve seen two views on how fast a developer can start contributing to the company. Some companies I was interviewed for were optimistic and expected developers to start contributing code within 2-4 weeks of joining the company while others view that it takes about 4 months for new hires to make any meaningful contribution. Although the expectations companies have between students and those who graduated from school differ a lot, most of my friends and I agree that you cannot really make much of an impact within 4 months of joining the company. Even my interview at Tim Hortons taught me that much. I was flatly rejected the job in the first minute of my interview upon learning that I was a student from a University over 400km away and just wanted a summer job. The interview was nonetheless enjoyable and I learned a lot from the interviewer on how much time, risks and costs the manager makes when hiring new employees. The same is true in the Build Team. It takes a long time to even get a builder started.
new build team members need “about three months of experience before they can confidently manage the build process on their own.”
-Understanding and Improving Build Teams
One of the key points I read from various papers and books is the importance to avoid making the build process a black box. Automation is a blessing and a curse at the same time. Automation makes life easier and more productive but it abstracts a lot of details builders need to know. Changes to the build process by non-build gurus can result in complex and messy build configurations whereby bad dependencies can cause builds to fail or slow down compilation. While I never worked with changes to the build process itself, I worked with the infrastructure to have the builds be kicked off automatically to all the inter and intra processes that go on during builds outside of the domain of writing the rules of what components needs to be built or how they link together. It’s hard to explain but there is a lot that goes on than simply running the makefile in a build system.
When the build system seems like a black box, it reduces confidence and increases time spent on debugging and finding information on how and what tools are being used to interact with a certain task and why the error came to be. I personally found it very useful listening to an advice a senior intern once told me which was to traverse and read various scripts that seems related to the build process and randomly spend time reading any documentation that may exist (if it does) on various means of source such as multiple sources of internal documentation (i.e. you may have more than one internal wiki and there may be internal websites people made that are long forgotten) and reading email and slack history. Although I do not understand most of the material I read, it does help me identify areas of where to look instead of being completely lost.
The paper suggests an approach to solving role ambiguity is to split the team into build operators and build engineers and split all the remaining tasks based on whether they primarily involve management or development duties. For context, build operators manage the build operations and team coordination. This means they are responsible for kicking off builds, monitoring the builds and communicate between teams of build breaks and working with the developers. Meanwhile, build engineers are responsible for creating and maintaining the build automation and tools. This suggestion is followed at the company I work in whereby the interns are the build operators and the full-timers are the build engineers. However, with a growing number of legacy systems and the restriction of resources, I find that both build engineers” and build operators are spending a lot of time resolving environment issues and trying to adapt legacy systems such that it meets security compliance.
In the topic of creating build tools, it is hard for “build engineers” to create and maintain automation tools without first having the experience of being a build operator. As a build operator, you are more exposed to the tools that exist and the limitations or the frustrations of the tool itself. Meanwhile, “build engineers” have little experience in utilizing the tools itself and would be unaware of all the tools that exists.
The biggest difference between interns and full time employees is the mentorship experience. All interns learn from the previous interns for 4 months on how to perform their tasks by working with them side by side. There is an inherent difference in knowledge sharing between new interns and new members of the Build team at my company. There is no great solution to the problem because it is completely unfeasible to have full-time employees to be mentored constantly by a senior member. Learning how to perform some tasks when the need for the knowledge isn’t needed is a problem as well. While it gives some exposure, it is not likely for new hires to retain the information nor understand the task itself.
Proposed Solution: If we were to take a look at the common sources of information builders to utilize at Microsoft, we find that tribal knowledge was used very frequently and was seen as a very useful source of information. This is a great concern because it fosters the need to rely on senior builders to pass the information in a very slow and timely manner, it causes severe knowledge gap and would be very devastating if the senior builder were to leave the team or company. I think this is the issue at my company whereby all of the current members of the Build team were given some black box and we are trying to figure out how the system works. The senior builders have all left and we are not given the advantage of learning from the builders who wrote all the tools and infrastructure since they no longer work at the company.


One way to facilitate knowledge sharing is to hold monthly education session whereby various members of the team take turns as a group or as individuals to study various parts about the Build System within or even outside the company and share with the team. Furthermore, the need to write documentation should be emphasized more. The documentation can be in any form, video or written. But documentation is also ineffective if no one knows about it so there needs to be some consideration on how to consolidate and expose all the documentation that exists into categories so that it can be quick to find the documentation. Lastly, perhaps the team should work on a side project to make a build simulator. This will be extremely hard and time-consuming but if builders are able to create a simulator that is isolated from production environments, senior builders can guide through new builders on how to do the tasks and give new builders the opportunity to practice various scenarios and tasks they do not perform before or at a regular basis. The simulator should be designed to be simple (because the actual build system and project can be way too complex) and isolated such that builders can simulate various tools without having the tool fail on them because of a dependency issue or a flaw in the tool itself. The reason why I really like the idea of creating a simulator is that new builders can be exposed, practice, and understand conceptually various tasks that exist rather than being taught and to never use it till the situation arises and it would be lost in their memory.
Side Note - Software Platforms
I mention it before, builders are responsible for the states of the builds on all supported platforms. Any change a developer makes cannot break any of the platforms whether it be a different operating system or different hardware. For instance, Counterstrike Global Offensive supports all three major operating systems: Linux, MacOS, and Windows.

If we were to look at the game requirements, we find that there are different requirements depending on the Operating System. For instance, on Windows we can see Direct X library is required but on Linux you need OpenGL and OpenAL libraries instead. DirectX is a graphics and sound library commonly used by PC Games and only exists on Windows. Any code running DirectX on Linux without some sort of emulator or translator will break. The installer for DirectX or any executable on Windows is formatted differently from how executables are formatted on Linux (i.e. ELF Format). A Linux computer will not understand how to read Windows executable, nor know how to load the dynamic library nor understand system calls which are functions that interact with the kernel or the operating system. Therefore, Linux uses OpenGl library to handle the graphics and OpenAL is used to handle the sound. Both of these libraries are multi-platform libraries and even support Windows (OpenGL used to be supported on MacOS). You can find OpenGL being used by games that offically support all 3 major operating systems such as Minecraft Java Edition where it uses Java which is a very portable language along with its usage of multiplatform libraries.


Another example is the Debian Kernel which is essentially the Linux Kernel version Debian uses. Debian supports many different architectures.

Notice how each architecture may represent the data size of a pointer or a long double differently? This can cause programs to behave differently which is very bad. Even different operating systems may represent data types differently and some data types may not even exist in another operating system. This can cause builds to break. These are build issues that are not rare to see when working on projects that can support different platforms. Also, notice how there are two different types of endian each CPU architecture can support (with the exception of CPU with bi-endian support where you just need to set a bit to change endians).
Below is an example of the difference between Windows and Linux in representing the data size of a long int. Windows represent long int with 4 Bytes causing any large value that would run on Linux perfectly fine to overflow and become a negative number. The compiler is smart enough to notice this and would give a warning but for demonstration purposes, I chose to ignore the warning.
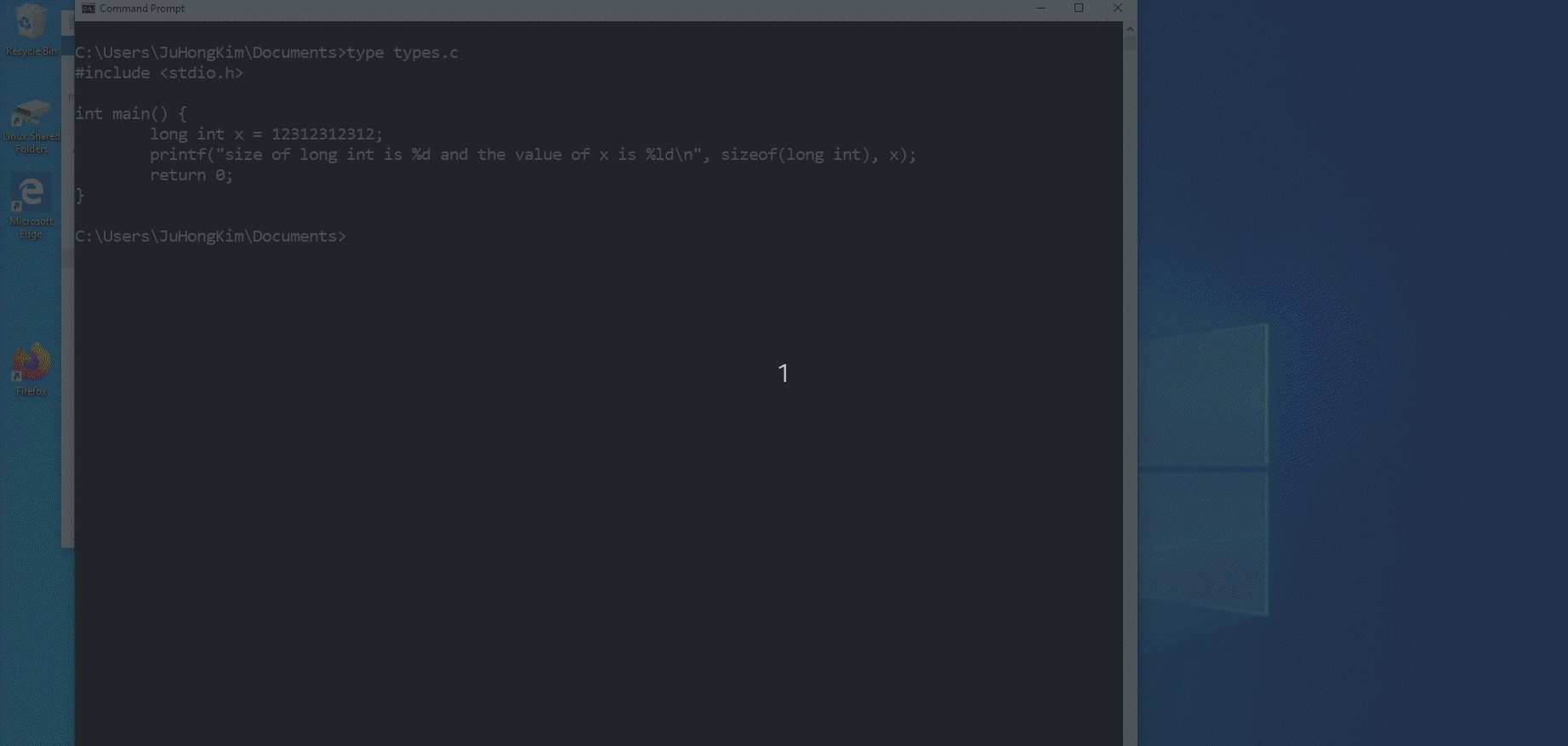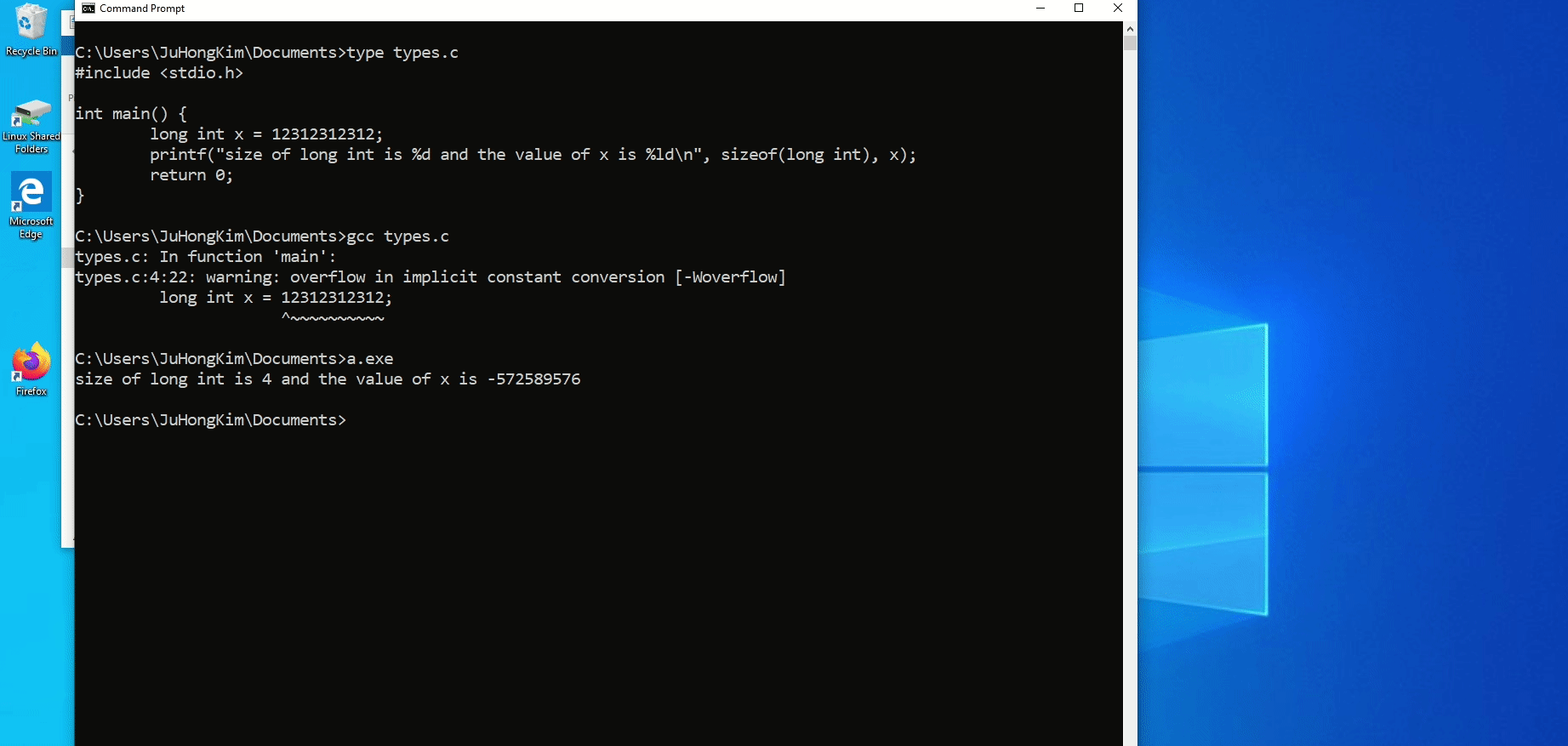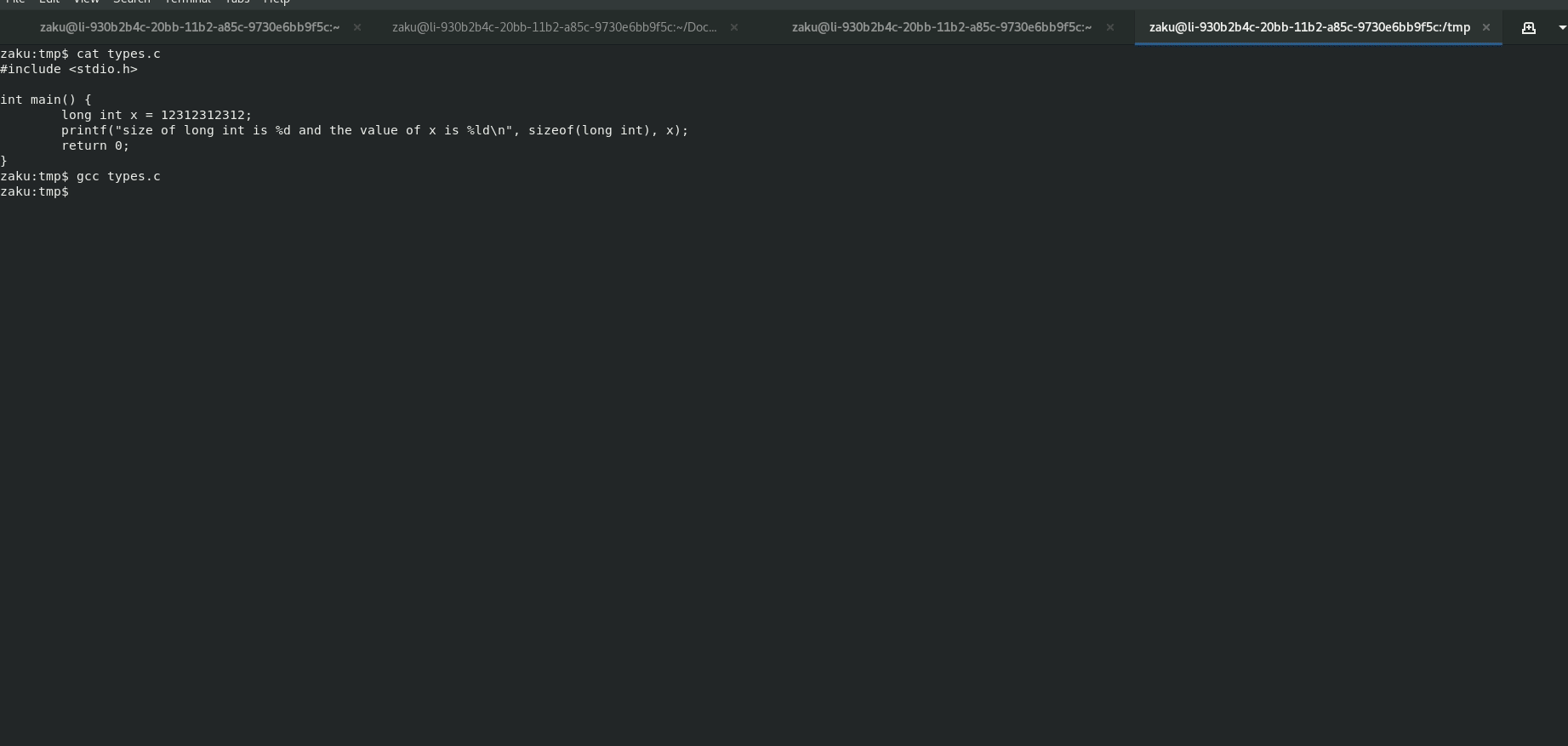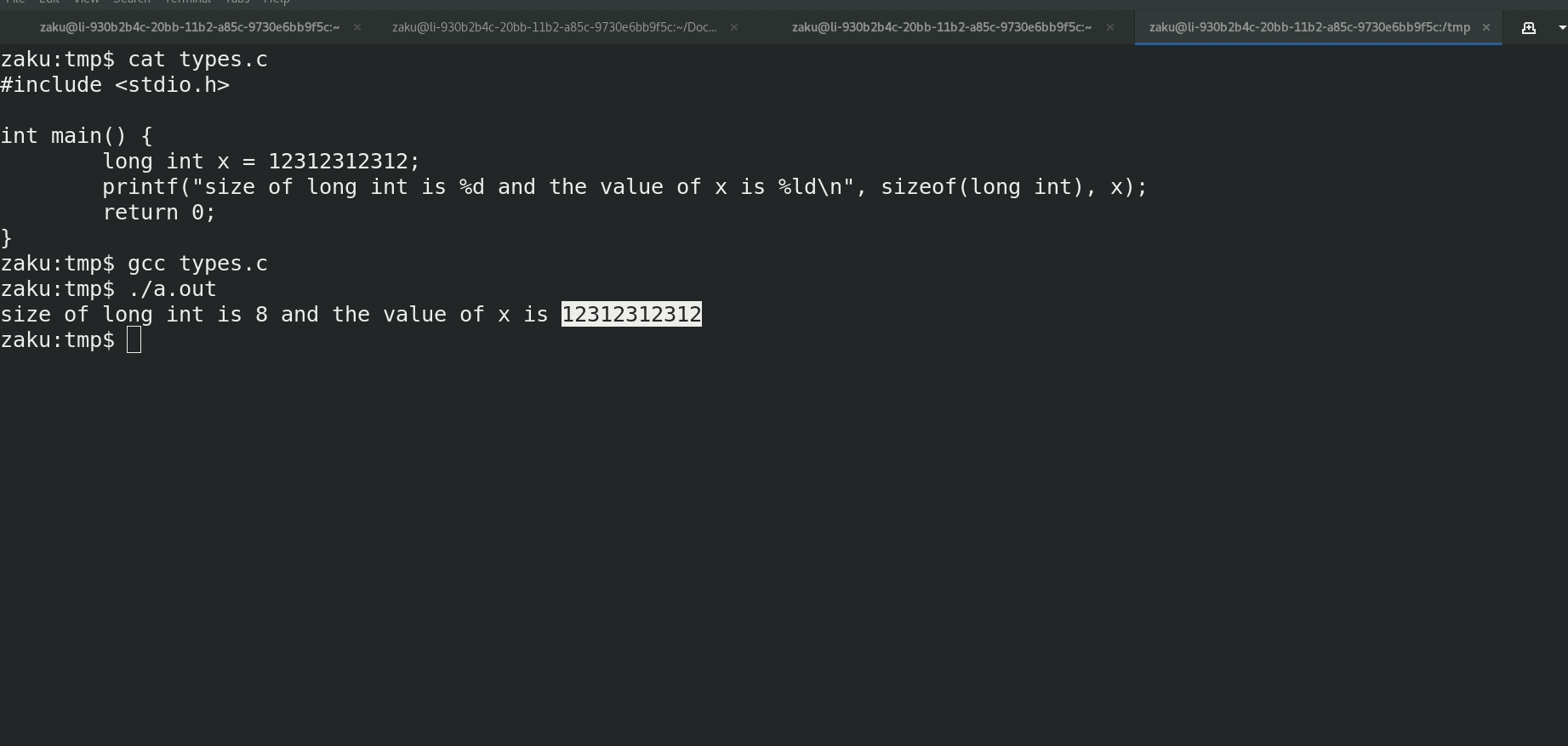
Random Note
amd64 does refer to builds running on AMD chips despite the name. It refers to Intel’s x86 Instruction set but the 64-bit version. AMD was the first to release the specifications for the 64 bit hence the name
A Note about Endian
Endian refers to the order of bytes. Little Endian (LE) stores the least significant byte at the smallest address while Big endian does the opposite.
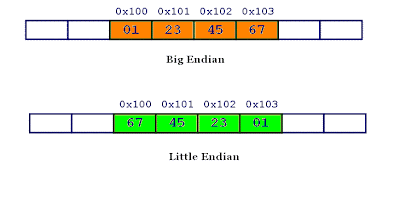
Why there are two different orders to represent bytes is a mystery to me. Perhaps there were several advantages of each architecture but I don’t think endian affects performance now.
Big Endian is more natural to us since we read numbers from left to right in English. For instance, in the number 123, 1 represents the highest number (i.e. $1\cdot100$) and 3 represents the smallest digit in the number (i.e. $3\cdot1$). Therefore I like to see things in Big endian order. It’s great to know that xdd, a hexdump tool, displays hex in big endian by default.
$ xxd /tmp/test.txt
00000000: 7069 6b61 6368 750a pikachu.
$ #xxd represents in Big Endian by default
$ xxd -e -g 2 /tmp/test.txt
00000000: 6970 616b 6863 0a75 pikachu.
You may have seen endian before when working on socket programming. Data being sent to the network is sent in big endian where the most significant byte is sent first. Little endian is probably more popular, at least among us consumers since x86 architecture is in little endian.

When working on forensics or in cybersecurity, sometimes you may see text in weird order such as “ehll oowlr”. This is due to the difference in endian mode. If we take endian into account, the text should be more readable.
$ echo "0000 6568 6c6c 206f 6f77 6c72 0a64" | xxd -r
ehll oowlr
$ echo "0000 6865 6c6c 6f20 776f 726c 640a" | xxd -r
hello world
Executing Programs on a Different Architecture
If you have ever programmed in assembly or taken a computer architecture, you’ll recall that each architecture has its own Instruction set. This means that every single assembly program has to be ported to run on another architecture since the instruction sets are different. This gets very annoying but there are reasons for this. It’s based on how the CPU is designed. When designing CPU, they are to follow certain instruction set architecture. Back in the days, there were a lot of chip manufacturers and their design philosophies were different. Therefore you had a lot of different architectures popping up since companies would not conform to a standard and following certain architectures may not be easily optimized for their certain use case at the time. Unlike Java where it can run anywhere or C which is fairly portable as long as it doesn’t touch very low-level stuff, assembly programs cannot be run on a different architecture. They simply don’t understand. Compilers were written to reflect the architecture it runs so that us high level programmers don’t ever need to learn the hardware of the computers we run. We just need to have a higher-level understanding of how computers work and the operating system we are working on. Fullstack developers, Java programmers, and mobile app developers don’t even need to understand the underlying operating system. It’s been so abstracted that there’s no real need to learn about them.
Below is an example of how different the assembly code is between ARM and x86. The CPU may speak in zeroes and ones but it needs to be in a format that the CPU understands. It’s like Latin and English. They both use similar character sets but an English speaker would not be able to understand Latin.

Here’s another example, trying to execute a program compiled on a Solaris machine on my laptop using an Intel chip. You’ll get an error because the computer cannot understand the instructions. This reminds me of a time when my father came to me for help since his program would no longer execute on his company’s server. Upon inspecting the binary, I soon realized the program was compiled from a Solaris workstation but the workstation he was trying to run on was running on PowerPC. Turned out the company moved the server from a Solaris workstation to a PowerPC workstation running Red Hat. My father didn’t realize that he couldn’t simply run a program running on a different CPU, so I had him just recompile the program since he did have the source code in hand.
$ ls | grep hello
helloAMD64.o
helloSPARC.o
$ file helloAMD64.o
helloAMD64.o: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.4, BuildID[sha1]=939dce5a136c499f9d64124f5e7cf29b1dd647b2, with debug_info, not stripped
$ file helloSPARC.o
helloSPARC.o: ELF 32-bit MSB executable, SPARC32PLUS, total store ordering, version 1 (Solaris), dynamically linked, interpreter /usr/lib/ld.so.1, with debug_info, not stripped
$ lscpu | grep Arch
Architecture: x86_64
$ ./helloAMD64.o
Hello World
$ ./helloSPARC.o
bash: ./helloSPARC.o: cannot execute binary file: Exec format errors
To conclude talking about platforms, I just wanted to talk about them to understand why programs may not be portable and just because your changes compiled and run fine on your development machine may break on a supported platform. We often see breaks come in because the developer did not consider other platforms and would use code that is not platform-independent.
DevOps
Works in an agile, collaborative environment to build, deploy, configure, and maintain systems, which may include software installations, updates, and core services.
Extracted from IBM DevOps Roles
or I like to refer it as
Combining development and operations best practices to continuously integrate (CI) through building and testing frequently to continuously deliver (CD) a good artifact to be ready for deployment
There are a few definitions of what DevOps is but I like to look at the practical role of DevOps to the organization. I see it as the practice of joining development and operations to deliver software more quickly through the use of CI/CD pipelines. One of the benefits of DevOps is catching bugs and deploying changes faster by building more frequently. So when a bug or build break occurs, it’s easier to catch early in the CI/CD pipeline when they are small and easier to manage. This also reduces idling because developers will no longer be waiting for the results of their changes and can work on a codebase that is up to date and more stable. It also means more releases since there are more builds.
The central idea of DevOps and CI/CD is that you want to automate the pipeline as much as possible and take a more shared responsibility approach between teams to increase response and understanding.

CI - Continuous Integration
As mentioned previously, CI is the process of building and testing changes frequently. This allows you to catch bugs much faster rather than waiting for the end of the day or even at the end of a sprint to build and test the changes into the project which often has disastrous results.
A lot of sources I read on CI and DevOps like to emphasize on the use of a version control system to have a single source of truth. To elaborate, CI focuses on building changes frequently to quicken development and software deliveries while maintaining quality. The first step to enable this benefit is to ensure there is a centralized code branch that is being built frequently. Building and testing on different copies of the projects or branches can cause issues whereby it gets hard to know which version works and the branch or version developers are working on could be out of date, unstable, or diverge from the project’s direction. You want to establish a centralized version where developers make changes based off stable, up-to date, and correct code base.

Here’s an overview of how a typical CI build process could work:
-
Developers push their changes to Github
-
An automation server would either be notified or notice a change has been pushed to Github and trigger a build via Jenkins
-
Jenkins would select a machine to run the builds
-
If the build is clean, it may either trigger another Jenkins job to run some basic build tests (or the build job may be part of a pipeline and the next stage is testing the build to ensure the build is not corrupted and passes all essential tests)
-
If the builds fail, the developers and manager would be notified of the failure and would be urged to take immediate action to resolve the issue

Example - React CI BUILDS

Here’s an example of where CI builds from React, a Javascript frontend framework, where builds are triggered when a PR is created. I assume all subsequent commits in the commit will trigger the CI builds as well. Anyhow, the reason why I want to highlight this is that the PR must go through extensive automated checks before the PR can be merged to master. This approach is great because it doesn’t require any active management to go around and catch developers to fix their changes. It’ll probably require an approval by the project maintainers but you can see how the project embraces Continuous integration.
Example - IBM Carbon
IBM Carbon is an open-source UX library for Javascript frameworks. It utilizes various tools to automate the builds, tests and has a bot to communicate with the developers when the builds fail.

Continuous Delivery/Deployment

CD refers to either continuous delivery or continuous deployment. The main difference between the two is whether you want explicit approval to deploy new changes automatically or not. Both delivery and deployment require creating artifacts (such as a website, app or an executable) that are in “ready state” (i.e. production-ready). Continuous deployment means you are automatically releasing the latest changes to production and this could be great if you want to reflect a change in the website as fast as possible. Perhaps you want to automatically deploy changes in a canary deployment fashion where you release the change to a small subset of servers or users. You often see this in social media where they roll out features incrementally to random selective users. This is a good way to have changes be tested in the real environment without facing huge consequences if the feature has severe issues or isn’t appreciated by the users. You can simply rollback the change. There are other deployment techniques such as blue-green deployment but I won’t talk about that in this post.
What I want to emphasize is that depending on the sensitivity and type of product you are working on will affect whether you will define CD as delivery or deployment. I typically see microservices, apps, and websites use continuous deployment. But I don’t think it’s a great idea to use continuous deployment on products that are very critical and can have an extremely severe impact on the consumers and society such as the databases or applications that involve in bank and credit card transactions. Any code changes that require a downtime to have the changes be reflected such as changing the database schema should not be deployed automatically.
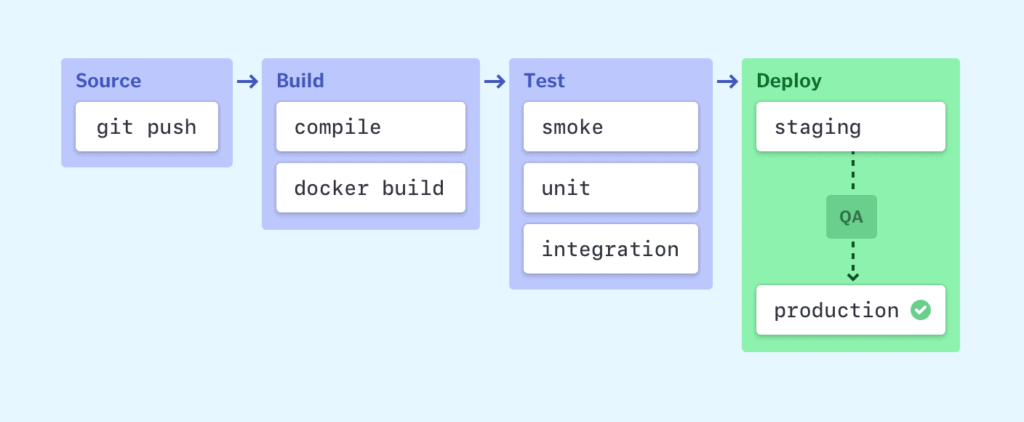
The picture below is a nice picture of tools that can be used in each stage of the CI/CD pipeline. Jenkins is an automation server that can schedule and kick-off jobs. For instance, Jenkins could be listening to any changes that get pushed to Github and if a change occurs, it’ll kick off a build on a node. Once the build passes, it can kick off another job/stage to upload the artifact to Artifactory, a repository on the cloud that stores artifacts. In case you’ve been wondering what I’ve been referring an artifact as, I referred to it as the binary or executable file that has been produced from the builds.

Conclusion
I hope you have more of an idea what a Builder does and their role in the organization. You may have notice my explanation of devOps isn’t complete nor great. I’m still learning about devOps as I am not very knowledgeable in this field.
More Resources
-
https://medium.com/linusplog/what-does-a-software-configuration-management-and-build-engineer-do-849e6ece9292
Image Sources - From the Ones I remember
SupportedArchitectures - Debian Wiki
Metrics to Improve Continuous Integration Performance - Harness
I am trying to put more credits to the images on my blogs, especially if I downloaded the images rather than linking them but it’ll be a while till I get a hang of it.